
티스토리 뷰
배경
행동대장 프로젝트에 무중단 배포를 적용하면서 고민한 내용을 공유한다.
목표
우리 팀의 목표는 실제로 서버 다운타임을 0에 가깝게 만드는 것이다. 무중단 배포 방식에는 대표적으로 롤링 배포, 블루-그린 배포, 카나리 배포가 있다. 카나리 배포는 서버가 단 2대인 현재 서비스에 적용하기에 과하다고 생각했다. 롤링 배포와 블루-그린 배포를 중점적으로 고려했다.
현재 인프라 아키텍처는 AZ를 A와 B로 분리한 프라이빗 서브넷에 EC2 한 대씩 두고, 퍼블릿 서브넷에 ALB를 둔 구조이다. ALB에는 EC2 2대에 로드밸런서를 연결한 상태이다. 그림은 다음과 같다.
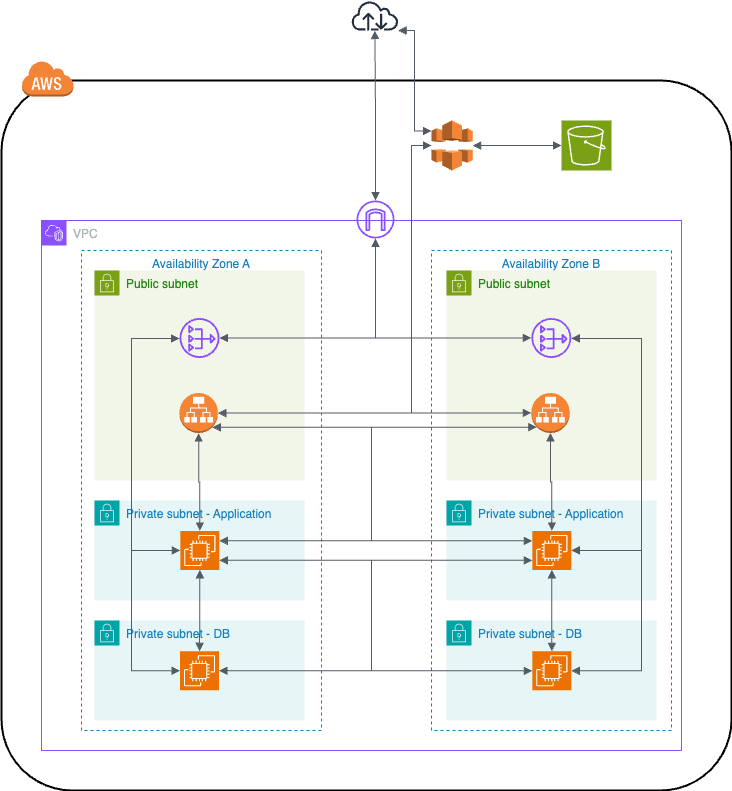
AWS ALB와 EC2 대상 그룹을 이용한 블루-그린 배포
이미 ALB를 사용하고 있기 때문에 AWS가 제공하는 EC2 Auto Scaling을 통한 블루-그린 배포를 하려 시도했다. 하지만 우테코 정책 상 Auto Scaling 권한이 없었다. Auto Scaling은 필요하지 않기 때문에 AWS CLI로 우회하여 ALB를 사용해서 배포하려 했지만, AWS CLI로 ALB에 접근할 수 있는 권한이 하나도 없었다.
권한을 요청하는 선택을 할 수도 있었지만, 팀에서는 현재 정책에서 문제를 해결하는 경험을 하기로 결정했다.
ALB와 EC2를 사용한 롤링 배포
다음으로 고려한 방법은 ALB를 사용해서 EC2에 순차로 롤링 배포하는 것이다.
ALB는 뒤에 있는 두 대의 EC2에 Health Check 하고 서버가 살아 있다면 요청을 프록시한다. EC2 한 대의 톰캣 프로세스를 중단하면 ALB는 해당 EC2의 Health Check에 실패한다. ALB는 실행 중인 EC2에만 요청을 프록시하게 되고, 그 사이에 다른 EC2에 새로운 애플리케이션을 배포하고 톰캣 프로세스를 실행하면 된다. 이 과정을 순차적으로 각 EC2마다 진행하는데, 그림으로 표현하면 다음과 같다.

이 방식을 적용했을 때, 다운 타임이 얼마나 발생하고 사용자 요청이 얼마나 실패하는지 확인하기 위해 테스트를 진행했다. 테스트는 Jmeter를 사용해서 100개의 동시 요청을 배포 전부터 후까지 무한히 반복했다. 결과는 다음과 같다.

위 그래프는 점이 초 단위로 기록되었고 초록색 점은 실패한 요청을 의미한다. 그림에서 상당히 많은 초록색 점들을 볼 수 있다. 초록색 점 무리는 2번 있는데, EC2 두 대에 순차로 배포할 때 각각 실패한 요청들이다. 위 그림을 해석하면, EC2에 배포할 때마다 20초 정도의 다운 타임이 발생했고 한 번의 배포에 40초의 다운 타임이 발생했다.
분명 ALB가 Health Check를 통해 로드밸런싱하고 있고 각 EC2에서 롤링 배포하는데 무엇이 문제일까? 문제는 ALB의 Health Check에 있었다. ALB의 default Health Check 주기는 15초다. Health Check 한 직후 ALB는 EC2가 가용 상태라고 인식하고 들어오는 요청을 프록시한다. 하지만 Health Check 한 직후에 배포가 일어나서 EC2가 불가용 상태가 될 수 있고, 프록시 된 요청은 서버에 도달하지 못하고 실패한다. 즉 운이 나쁘면 15초의 다운 타임 동안 서버에 요청이 프록시되고, 또 새로운 톰캣 프로세스가 실행되기까지 추가 시간이 걸린다.
추가로 롤링 배포 방식은 하위 호환을 보장하지 못하는 배포가 일어날 때 문제가 생길 수 있고, 일부 EC2에 부하가 커진다는 단점을 고려해야 한다. 현재는 하위 호완을 보장하는 배포를 하기에 문제는 없지만, 2대의 EC2를 사용하는 상황에서 롤링 배포를 하게 되면 한 대의 서버가 모든 부하를 감당해야 한다. 현재 상황에서 안정적인 배포를 위해서는 1대의 서버를 추가해야 한다.
Nginx를 사용한 블루-그린 배포
위 문제를 해결하기 위해 Nginx 도입을 결정했다.

배포 전에는 80 포트에 바인딩된 Nginx 프로세스와 8080 포트에 바인딩된 톰캣 프로세스가 실행 중이다. Nginx로 들어오는 요청은 8080포트로 포트포워딩한다. 배포가 시작되고, 새로운 톰캣 프로세스를 실행하고 8081에 바인딩한다. 그다음 Nginx의 포트포워딩을 8080 포트에서 8081 포트로 전환한다.
이 방식을 적용하면 과연 얼마의 다운 타임이 발생할까? Nginx의 설정을 변경할 때 Reload가 필요하다. 이 Reload하는 시간은 사용자 요청을 받지 못하는 시간인데, Nginx Reload 시간은 찰나의 순간이다. 그 순간에 들어온 요청은 정상 응답하기 어렵지만 이 정도는 사용자 경험에 크게 영향을 미치지 않을 거라 생각했다.
다운 타임이 얼마나 발생하고, 사용자 요청이 얼마나 실패하는지 확인하기 위해 테스트를 진행했다. 테스트는 Jmeter를 사용해서 100개의 동시 요청을 배포 전부터 후까지 무한히 반복했다. 결과는 다음과 같다.

초록색 점이 2번 찍힌 것을 확인할 수 있다. 단 2번의 순간에 극소수의 요청만 실패했다. 실패한 응답을 확인해 보자.

단 4개의 요청이 찰나의 순간에 실패한 것을 확인할 수 있었다. 요청 시간을 확인하면 40초 부근에서 3개의 요청이, 45초 부근에서 1개의 요청이 실패했다. 이를 통해 2대의 서버 각각에서 0.002초 미만의 다운 타임이 발생했다는 것을 확인할 수 있다.
이 방식으로 우리 팀은 무중단 배포를 할 수 있게 되었고, 블루-그린 배포라서 하위 호환이 보장되지 않아도 적용할 수 있다.
추가적인 고민
2ms의 다운 타임 정도는 웬만한 규모의 서비스에서 전혀 영향을 주지 않기에 무중단 배포에 성공했다. ALB를 제어할 권한이 없어서 Nginx를 도입하였는데, 처음에는 단순히 배포만을 위해 Nginx를 사용하는 것에 거부감이 들었다. 하지만 ALB의 Health Check 최소 시간인 5초로 설정하더라도 최소 5초의 다운 타임이 발생하고, 이를 2ms로 줄일 수 있기에 Nginx 도입이 합리적으로 보인다.
다운 타임인 2ms 조차 줄일 방법은 없을까? 배포를 위해 서버가 중단되기 전에 ALB의 Health Check에 선제적으로 Down을 응답할 수 있다면 완전한 무중단을 할 수 있다. 배포 전에 Nginx 단에서 Health Check에 Down을 응답하는 방법, 애플리케이션에 서버를 Down 상태로 만드는 API를 만드는 방법 등 여러 고민을 했다. 하지만 2ms를 줄이기 위해 구현할 부분과 관리할 범위가 늘어나기에 현재 방식이 합리적이란 결론을 내렸다.
'프로젝트 - 행동대장' 카테고리의 다른 글
| 영수증 이미지 최적화 방법과 여러 구현 방식 (1) | 2024.10.09 |
|---|---|
| S3에 저장된 이미지 응답 시간 테스트 (0) | 2024.10.07 |
| 8인의 협업, 갈등 상황에서 찾은 나의 역할 (1) | 2024.09.21 |